こんにちは。今回はプログラミング言語Javaの文字列の判定について記事にしました。与えられた文字列について、先頭と末尾が特定の文字列であることを判定する方法について、以下の2つを試しました。
- startsWith()とendsWith()を使う。
- 正規表現を使う。
上記のサンプルを作成した後、処理速度の比較をしました。
判定する文字列
以下の文字列が配列で与えられたとします。
- Andy:Brazil:2019,2020
- Jimmy:India:2017,2018
- Jimmy:China:2019,2020
- Joe:China:2020,2021
- Steve:India:2022
上記のように、人名、所属する国、所属していた年が、以下のように区切られた文字列として与えらたという想定です。
| 人名 | 区切り文字 | 国 | 区切り文字 | 西暦(カンマ区切り) |
|---|---|---|---|---|
| Jimmy | : | China | : | 2019,2020 |
ただし、国の部分が空文字になるなどの特別な場合は扱わないとします。
今回は、上記の文字列で、以下の条件を満たす文字列だけ抽出するということを目的とします。
| 先頭 | 末尾 |
|---|---|
| Jimmy: | ,2020 |
この目的を満たすプログラムの実装方法について、以下の2つを考えました。
- StringクラスのstartsWith()メソッドとendsWith()メソッドで文字列を判定する。
- Patternクラスを使って、正規表現で文字列を判定する。
なお、与えられた文字列の形式次第では、String#split()メソッドを使うこともできると思います。今回は文字列にコロンとカンマが混在している想定なので、このメソッドは使いません。
方法1: startsWith()とendsWith()で判定
最初の方法はStringクラスのstartsWith()とendsWith()を使う方法です。
例えば文字列strに対して、str.startsWith([第1引数])という記述でメソッドを呼び出せます。strが第1引数で指定した文字列で始まる場合、このメソッドはtrueを返却します。endsWith()メソッドも同様の記述で呼び出せます。strが第1引数で終わる場合、trueが返却されます。
startsWith()とendsWith()の簡単な使い方は以下です。
簡単な例
String str = "ABC1234abcd";
boolean rst;
System.out.println("startsWithの練習");
rst = str.startsWith("ABC");
System.out.println(rst);
rst = str.startsWith("BC");
System.out.println(rst);
System.out.println("endsWithの練習");
rst = str.endsWith("bcd");
System.out.println(rst);
rst = str.endsWith("bc");
System.out.println(rst);結果
startsWithの練習
true
false
endsWithの練習
true
false上記のようにString型変数strに対して、メソッドを呼び出して使います。上記2つのメソッドと論理演算子&&を使うことで、与えれた文字列について、開始と終了の文字列を判定することが可能です。
以下、サンプルです。
方法1
import java.util.ArrayList;
import java.util.List;
public class Test001 {
public static void main(String[] args) {
new Test001().test();
}
public void test() {
String prefix = "Jimmy:";
String suffix = ",2020";
System.out.println("判定条件");
System.out.println("先頭|" + prefix);
System.out.println("末尾|" + suffix);
List<String> strs = getData();
for (String str : strs) {
boolean rst = judge_1(str, prefix, suffix);
System.out.println("-----------------------");
System.out.println("対象:" + str);
System.out.println("結果:" + rst);
}
}
public boolean judge_1(String str, String prefix, String suffix) {
return str.startsWith(prefix) && str.endsWith(suffix); // (1)
}
public List<String> getData() {
List<String> strs = new ArrayList<String>();
strs.add("Andy:Brazil:2019,2020");
strs.add("Jimmy:India:2017,2018");
strs.add("Jimmy:China:2019,2020");
strs.add("Joe:China:2020,2021");
strs.add("Steve:India:2022");
return strs;
}
}結果
判定条件
先頭|Jimmy:
末尾|,2020
-----------------------
対象:Andy:Brazil:2019,2020
結果:false
-----------------------
対象:Jimmy:India:2017,2018
結果:false
-----------------------
対象:Jimmy:China:2019,2020
結果:true
-----------------------
対象:Joe:China:2020,2021
結果:false
-----------------------
対象:Steve:India:2022
結果:false上記プログラムのjudge_1()メソッドの(1)の個所は「aかつb」の結果を返却しています。aの個所は先頭の判定、bの個所は末尾の判定です。「aかつb」がreturn文1つにまとめれてます
(1)の部分については、それぞれの結果を変数に格納したい場合、以下のように書けます。
変数を使った書き方
public boolean judge_1(String str, String prefix, String suffix) {
boolean a = str.startsWith(prefix);
boolean b = str.endsWith(suffix);
boolean rst = a && b;
return rst;
}それぞれの結果を表にしたものが以下です。
| a | b | aかつb | 文字列 |
|---|---|---|---|
| false | true | false | Andy:Brazil:2019,2020 |
| true | false | false | Jimmy:India:2017,2018 |
| true | true | true | Jimmy:China:2019,2020 |
| false | false | false | Joe:China:2020,2021 |
| false | false | false | Steve:India:2022 |
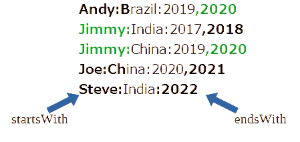
3番目の文字列だけが、先頭と末尾の条件を満たしています。
方法2: 正規表現で判定する
2番目の方法は正規表現を使う方法です。次の2つのクラスを使います。
- java.util.regex.Pattern
- java.util.regex.Matcher
次のステップで正規表現にマッチするかどうかをチェックできます。
- Patternクラスのcompile()メソッドを呼び出す。
- 上記で返却されたPatternオブジェクトで、matcher()メソッドを呼び出す。
- 上記で返却されたMatcherオブジェクトで、matches()メソッドを呼び出す。
上記は1行にまとめて記述することもできますが、それぞれを変数に格納した書き方をする場合、以下のように記述できます。
簡単な例
String regex = "A.*B";
String target = "A1234B";
Pattern pattern = Pattern.compile(regex); // (1)
Matcher matcher = pattern.matcher(target); // (2)
boolean rst = matcher.matches(); // (3)
System.out.println("正規表現: " + regex);
System.out.println("対象: " + target);
System.out.println("結果: " + rst);結果
正規表現: A.*B
対象: A1234B
結果: true(1)でPatternオブジェクトを生成しています。引数に指定している変数regexには、先頭と末尾の条件を記述した正規表現の文字列が格納されています。正規表現の「.*」は「任意の文字の0回以上」を表します。なお、「.+」で「任意の文字の1回以上」です。
(2)では(1)で生成したオブジェクトに対して、matcher()メソッドを呼び出しています。引数には検索の対象となる文字列を指定します。今回はString型変数targetを指定しています。このメソッドでMatcherオブジェクトが生成されます。
(3)では(2)で取得したオブジェクトに対して、matches()メソッドを呼び出しています。このメソッドはboolean型の値を返却します。(2)で指定した文字列が(1)で指定した正規表現を満たす場合、trueが返却されます。
上記のプログラムの(1)から(3)は1行にまとめることもできます。
以下、今回の目的の方法2のサンプルです。
方法2
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Pattern;
public class Test002 {
public static void main(String[] args) {
new Test002().test();
}
public void test() {
String prefix = "Jimmy:";
String suffix = ",2020";
System.out.println("判定条件");
System.out.println("先頭|" + prefix);
System.out.println("末尾|" + suffix);
List<String> strs = getData();
for (String str : strs) {
boolean rst = judge_2(str, prefix, suffix);
System.out.println("-----------------------");
System.out.println("対象:" + str);
System.out.println("結果:" + rst);
}
}
public boolean judge_2(String str, String prefix, String suffix) {
return Pattern.compile(prefix + ".*").matcher(str).matches()
&& Pattern.compile(".*" + suffix).matcher(str).matches();
}
public List<String> getData() {
List<String> strs = new ArrayList<String>();
strs.add("Andy:Brazil:2019,2020");
strs.add("Jimmy:India:2017,2018");
strs.add("Jimmy:China:2019,2020");
strs.add("Joe:China:2020,2021");
strs.add("Steve:India:2022");
return strs;
}
}結果
判定条件
先頭|Jimmy:
末尾|,2020
-----------------------
対象:Andy:Brazil:2019,2020
結果:false
-----------------------
対象:Jimmy:India:2017,2018
結果:false
-----------------------
対象:Jimmy:China:2019,2020
結果:true
-----------------------
対象:Joe:China:2020,2021
結果:false
-----------------------
対象:Steve:India:2022
結果:false方法1と同じように、3番目の文字列がtrueと判定されました。judge_2()メソッドのreturn文の個所は、「aかつb」の形です。aの部分で、文字列の先頭を判定し、bの部分で文字列の末尾を判定しています。a、bそれぞれは、先述の例の(1)から(3)を1行にまとめた形です。
Patternの処理速度
方法1と方法2を比較
処理時間の比較のため、上記の方法1と方法2を以下のように1つのテスト用クラスにまとめました。
処理時間のテスト
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Pattern;
public class Test003 {
public static void main(String[] args) {
Test003 test003 = new Test003();
for (int i = 0; i < 5; i++) {
test003.test();
}
}
public void test() {
String prefix = "Jimmy:";
String suffix = ",2020";
List<String> strs = getData();
int max = 300000;
long start, end;
// 方法1の測定
start = System.currentTimeMillis();
for (int i = 0; i < max; i++) {
for (String str : strs) {
judge_1(str, prefix, suffix);
}
}
end = System.currentTimeMillis();
System.out.println("方法1: " + (end - start));
// 方法2の測定
start = System.currentTimeMillis();
for (int i = 0; i < max; i++) {
for (String str : strs) {
judge_2(str, prefix, suffix);
}
}
end = System.currentTimeMillis();
System.out.println("方法2: " + (end - start));
}
public boolean judge_1(String str, String prefix, String suffix) {
return str.startsWith(prefix) && str.endsWith(suffix);
}
public boolean judge_2(String str, String prefix, String suffix) {
return Pattern.compile(prefix + ".*").matcher(str).matches()
&& Pattern.compile(".*" + suffix).matcher(str).matches();
}
public List<String> getData() {
List<String> strs = new ArrayList<String>();
strs.add("Andy:Brazil:2019,2020");
strs.add("Jimmy:India:2017,2018");
strs.add("Jimmy:China:2019,2020");
strs.add("Joe:China:2020,2021");
strs.add("Steve:India:2022");
return strs;
}
}結果
方法1: 42
方法2: 918
方法1: 43
方法2: 684
方法1: 5
方法2: 642
方法1: 6
方法2: 648
方法1: 5
方法2: 642上記は方法1と方法2をそれぞれ300000回繰り返すという処理を合計5回実行しています。
結果を表にすると以下の通りです。
| No. | 方法1 | 方法2 |
|---|---|---|
| 1 | 42 | 918 |
| 2 | 43 | 684 |
| 3 | 5 | 642 |
| 4 | 6 | 648 |
| 5 | 5 | 642 |
judge_2()メソッドの処理の方が比較的かなり処理時間が長いです。原因として考えられるのは、Patternオブジェクトが毎回生成される書き方をしている点です。メソッドを繰り返し呼び出す場合、この部分のために処理時間が長くなります。
改良して比較
judge_2()メソッドの処理時間が短くなるように、以下のように判定用のクラスを作りました。
ソース
import java.util.regex.Pattern;
public class MyJudge {
String prefix;
String suffix;
Pattern pattern_1;
Pattern pattern_2;
public MyJudge(String prefix, String suffix) {
this.prefix = prefix;
this.suffix = suffix;
this.pattern_1 = Pattern.compile(prefix + ".*");
this.pattern_2 = Pattern.compile(".*" + suffix);
}
public boolean judge_1(String str) {
return str.startsWith(prefix) && str.endsWith(suffix);
}
public boolean judge_2(String str) {
return pattern_1.matcher(str).matches()
&& pattern_2.matcher(str).matches();
}
}コンストラクタは、先頭と末尾の条件にする文字列を引数で受け取ります。受け取った値はメンバ変数prefixとsuffixに格納します。また、引数を使って、正規表現での判定用のPatternオブジェクトを生成しています。メンバ変数pattern_1とpattern_2に生成したインスタンスを格納しています。judge_2()メソッドでは、それらメンバ変数に対してmatcher()メソッドを呼び出すようにしています。
処理時間の比較を以下のプログラムで実施しました。
ソース
import java.util.ArrayList;
import java.util.List;
public class Test004 {
public static void main(String[] args) {
Test004 test004 = new Test004();
for (int i = 0; i < 5; i++) {
test004.test();
}
}
public void test() {
List<String> strs = getData();
String prefix = "Jimmy:";
String suffix = ",2020";
MyJudge myJudge = new MyJudge(prefix, suffix); // (1)
int max = 300000;
long start, end;
start = System.currentTimeMillis();
for (int i = 0; i < max; i++) {
for (String str : strs) {
myJudge.judge_1(str); // (2)
}
}
end = System.currentTimeMillis();
System.out.println("方法1: " + (end - start));
start = System.currentTimeMillis();
for (int i = 0; i < max; i++) {
for (String str : strs) {
myJudge.judge_2(str); // (3)
}
}
end = System.currentTimeMillis();
System.out.println("方法2: " + (end - start));
}
public List<String> getData() {
List<String> strs = new ArrayList<String>();
strs.add("Andy:Brazil:2019,2020");
strs.add("Jimmy:India:2017,2018");
strs.add("Jimmy:China:2019,2020");
strs.add("Joe:China:2020,2021");
strs.add("Steve:India:2022");
return strs;
}
}結果
方法1: 46
方法2: 361
方法1: 35
方法2: 266
方法1: 4
方法2: 275
方法1: 6
方法2: 227
方法1: 5
方法2: 214(1)では、比較用に作ったMyJudgeクラスのインスタンスを生成しています。(2)と(3)で、そのインスタンスに対して、メソッドを呼び出しています。
処理時間は以下の表のとおりです。
| No. | 方法1 | 方法2 |
|---|---|---|
| 1 | 46 | 361 |
| 2 | 35 | 266 |
| 3 | 4 | 275 |
| 4 | 6 | 227 |
| 5 | 5 | 214 |
方法2の実行時間が短くなりました。Patternオブジェクトの生成を1度に済ませているため、処理時間はかなり短縮されました。それでも方法1の方が速いです。
正規表現を1つにまとめることができれば、方法2はより速くなると思います。正規表現についていくつかの解説を調べましたが、難しそうなので今回は断念しました。
以上、参考になれば幸いです。